
Reinforcement Learning agents excel at mastering complex games and controlling robotic systems, yet their performance can suddenly deteriorate without warning. The root cause of this instability lies in a trio of powerful yet risky techniques collectively known as the “Deadly Triad.” This article delves into the fundamental source of this instability, examining how function approximation, bootstrapping, and off-policy learning converge to create a perfect storm for divergence. It also reveals how groundbreaking innovations within the Deep Q-Network (DQN) finally provided the solution to this challenge.
To understand why modern Reinforcement Learning can be so unstable, we must first appreciate the breakthrough that made it powerful. The journey starts with a fundamental limitation in classic RL.
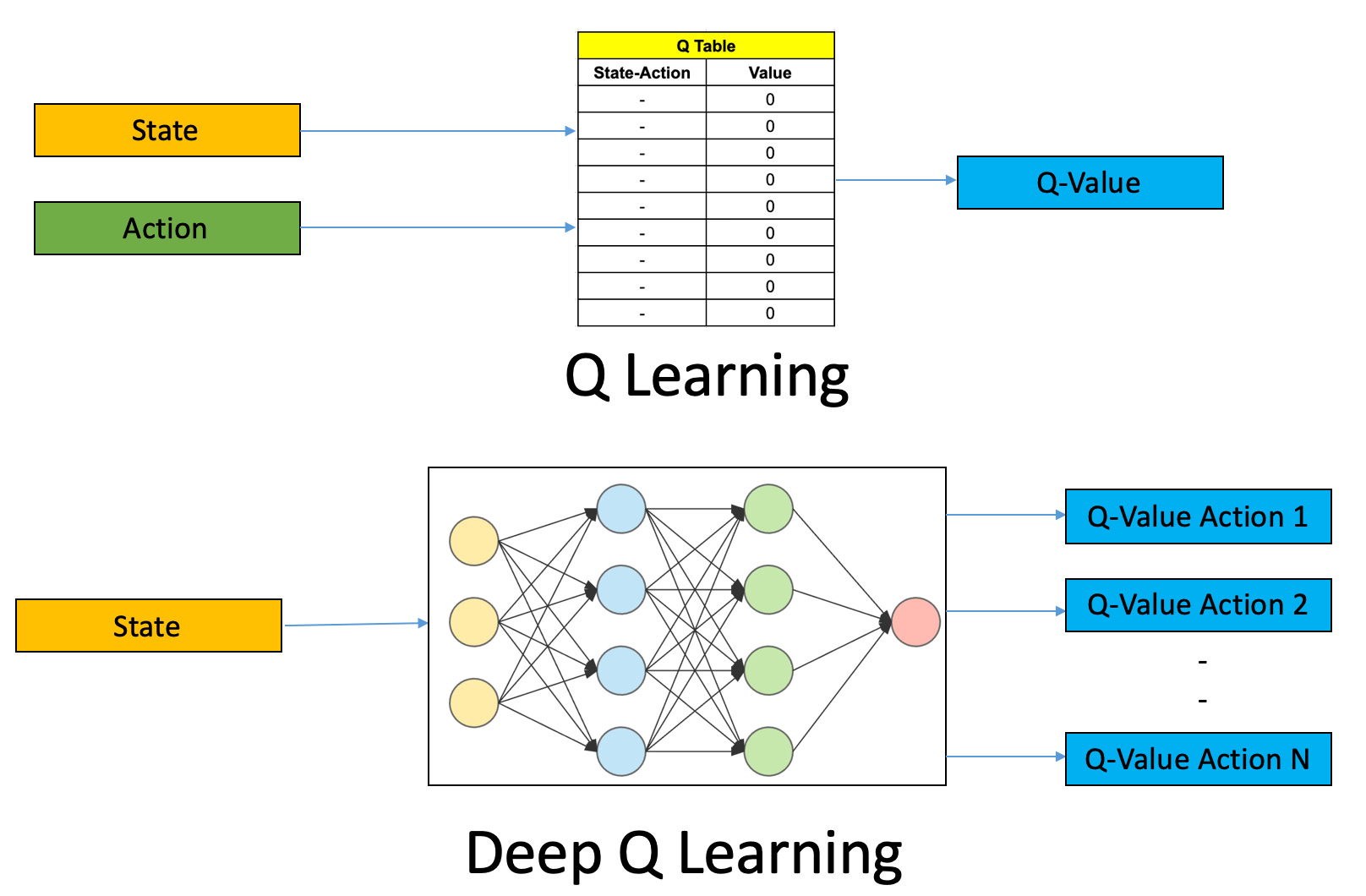
Early RL methodologies, like tabular Q-learning, rely on a simple lookup table with a distinct entry for every possible state, storing the learned value for each action. This is effective for small, discrete environments like a simple grid world.
However, this tabular approach fails when applied to complex problems due to the "curse of dimensionality." A game like chess has more unique board positions than atoms in the observable universe, making a lookup table physically impossible. Even an Atari game with an 84x84 pixel screen has a state space so vast that an agent would almost never encounter the exact same pixel configuration twice. This scaling problem renders tabular methods impractical for any environment with a large or continuous state space.
If we cannot store the value for every state, the alternative is to approximate it. This is the central idea behind Value Function Approximation (VFA). Instead of a table, we use a parameterized function—typically a deep neural network—that takes a state as input and outputs an estimated value. We can denote this approximator as Vθ(s) , where θ represents the function's learnable parameters (e.g., network weights). The goal is to find the optimal parameters that produce an accurate estimate of the true value function across the entire state space.
This shift provides two profound advantages. First, VFA is memory-efficient, requiring storage only for the fixed-size parameters , independent of the environment's size. Second, and more importantly, it enables generalization. A well-trained approximator can infer the value of unseen states based on their similarity to experienced ones. A tabular method has no concept of similarity; every unvisited state is a blank slate. Generalization is the game-changer that allows agents to learn meaningful policies in complex environments.
To train the approximator, we can frame the problem as a supervised learning task. Using Temporal-Difference (TD) learning, we generate a target value for a state by summing the immediate reward and the discounted value of the next state:
We then use an optimization algorithm like Stochastic Gradient Descent (SGD) to adjust the parameters to minimize the error between the network's prediction and this TD target.
Function approximation is essential for solving large-scale problems. However, when combined with two other standard RL techniques—bootstrapping and off-policy learning—it forms the "Deadly Triad." These three components are not design flaws; they are powerful tools. But together, they can create a feedback loop that causes the agent's value estimates to spiral out of control, a phenomenon known as divergence.
The first component is the use of a parameterized function, like a neural network, to estimate values. Its key strength is generalization: the ability to estimate values for unseen states by recognizing similarities to known ones.
While essential, generalization introduces a vulnerability. In a tabular method, updating one state's value has no effect on others. With function approximation, an update to one state's value modifies the network's shared parameters, causing ripple effects that alter value estimates for many related states. A single inaccurate estimate can therefore propagate its error across a wide swath of the state space, laying the groundwork for instability.
The second component is bootstrapping, a core concept in Temporal-Difference (TD) learning. Bootstrapping means we update our value estimate for a state using the estimated value of the next state. The TD target, Reward + discount_factor * Q(next_state, next_action), relies on a value produced by our own, still-learning approximator.
This process of "learning a guess from a guess" is highly sample-efficient, but it creates a non-stationary or "moving target" problem. Each time the algorithm adjusts the network's parameters, the target values themselves change because they are a function of the same parameters. The agent is perpetually chasing an objective that shifts with every update, an inherently unstable process that can struggle to converge.
The final ingredient is off-policy learning, where the agent learns about one policy (the target policy, typically optimal) while following another (the behavior policy, typically exploratory). This allows the agent to explore its environment effectively while still learning about the optimal way to behave. It also enables powerful techniques like experience replay.
The trade-off is a distribution mismatch: the training data comes from a different distribution of states and actions than the target policy would produce. The danger lies in updating Q-values for actions the target policy would never select. If the agent overestimates the value of a suboptimal, exploratory action, this error gets incorporated into the network. Due to bootstrapping, this flawed value can then become the target for other states, and function approximation generalizes this fiction. The agent begins learning about non-existent high-value pathways based on data that does not reflect optimal behavior.
When all three components operate together, a vicious cycle emerges:
A small estimation error is introduced, perhaps from an off-policy exploratory action.
Bootstrapping uses this erroneous value to create an inaccurate TD target for a preceding state.
The function approximator trains on this flawed target, propagating the error to a wider set of similar states via generalization.
This increases the likelihood that another bootstrapped update will select one of these newly overestimated values, further amplifying the error.
")
Each update, instead of moving the Q-values closer to their true figures, can push them further away, creating an uncontrolled feedback loop where value estimates spiral towards infinity.
This theoretical feedback loop manifests as catastrophic failure during training. The most direct consequence is divergence, where the network's value predictions spiral out of control. This typically appears as exploding Q-values, which grow without bound, or an oscillating policy, where the agent's strategy thrashes between contradictory behaviors as the underlying values fluctuate dramatically.
This instability is exacerbated because an RL agent's experience is sequential and highly correlated. Neural networks learn best from independent and identically distributed (IID) data. An RL agent, however, might spend hundreds of consecutive time steps in one part of the environment, generating a stream of similar training samples. Feeding this correlated data to the network acts as an accelerant for the Deadly Triad's feedback loop, as an estimation error is immediately reinforced by subsequent, nearly identical states.
For much of the 1990s and early 2000s, the Deadly Triad was a fundamental barrier that stalled progress in scaling reinforcement learning to complex, high-dimensional problems. Overcoming it required foundational innovations to stabilize the training process itself.
The breakthrough came in 2015 with the Deep Q-Network (DQN), which introduced two powerful innovations that directly countered the Triad's instability.
To break the harmful effects of correlated data, DQN introduced Experience Replay. Instead of training on experiences as they occur, the agent stores transitions—(state, action, reward, next_state)—in a large memory buffer. During training, the algorithm samples a random minibatch of transitions from this buffer.
By sampling randomly, we break the temporal correlations in sequential experience. The network learns from a diverse set of transitions drawn from many different time steps, more closely approximating the IID data assumption that underpins stable deep learning. This stabilizes training by averaging updates over many past behaviors, preventing the network from getting stuck in feedback loops driven by a narrow slice of recent data.
To solve the "moving target" problem, DQN introduced a second, separate target network. This creates a two-network architecture:
The online network is the main network being trained, with its weights updated at every step.
The target network is a clone of the online network whose weights are held frozen. They are only updated periodically (e.g., every 10,000 steps) by copying the weights from the online network.
When calculating the TD target (Reward + γ * max_a' Q(s', a')), the crucial max Q(s', a') term is computed using the stable, frozen target network. This means that for thousands of updates, the learning objective remains stationary. The online network has a fixed target to chase, which dramatically reduces the oscillations caused by bootstrapping with a rapidly changing value function.
These two innovations, working in concert, dismantled the dangerous feedback loop of the Deadly Triad. Experience replay addresses the instability from using a function approximator on correlated, off-policy data, while the fixed target network solves the moving target problem inherent in bootstrapping.
DQN was the first algorithm to successfully train deep neural networks for reinforcement learning on complex, high-dimensional tasks. Its landmark achievement was demonstrating human-level performance across a suite of Atari 2600 games, learning directly from raw pixel data. This foundational breakthrough unlocked the modern era of Deep RL, and its core principles remain standard components in many advanced algorithms today.
The convergence of function approximation, bootstrapping, and off-policy learning—the "Deadly Triad"—once rendered deep value-based reinforcement learning intractably unstable. The introduction of Deep Q-Networks, with its elegant solutions of experience replay and a fixed target network, provided the crucial stability needed to tame this divergence. This foundational breakthrough didn't just solve a technical problem; it unlocked the potential of Deep RL, enabling the remarkable achievements we see today and establishing core principles that continue to influence the design of modern agents.
Thank you for reading my thoughts. This newsletter is a humble space where I share my journey in RL, Generative AI, and beyond. If you find value here, I’d be grateful if you subscribed and shared it with friends. Your feedback, both kind and constructive, helps me grow.
With gratitude,
Narasimha Karthik J