
Model-free reinforcement learning enables agents to learn directly from their experiences. This article delves into the process by exploring the fundamental duality between prediction and control—the distinction between evaluating a strategy and finding an optimal one. We will examine how this relationship drives learning through Generalized Policy Iteration and address the critical challenge of balancing exploration and exploitation to achieve true mastery.
Reinforcement learning problems begin with a critical question: Does the agent have access to the underlying rules of its world? The answer splits the field into two paradigms.
Imagine solving a maze with a complete blueprint. You know every path, dead end, and the reward's location. This is model-based learning. The agent has an explicit model of the environment, which includes:
The transition function: The probability of moving to a new state from a current state, given an action.
The reward function: The reward received for taking an action in a state.
With this blueprint, the agent's task is planning. It can internally simulate action sequences to find the optimal path without taking a physical step. Techniques like dynamic programming (DP) thrive here, allowing an agent to compute an optimal policy by iterating over the known rules.
Now, imagine being in the same maze with no map. The only way to learn is through trial and error: take a step, observe the outcome, and remember what worked. This is model-free learning.
The agent does not have access to the environment's underlying Markov Decision Process (MDP). Instead, it learns a policy by directly estimating value functions from its experience—the raw stream of states, actions, and rewards. While this seems like a disadvantage, for complex real-world problems where dynamics are unknown (like financial markets or robot locomotion), learning from direct experience is the only viable path.
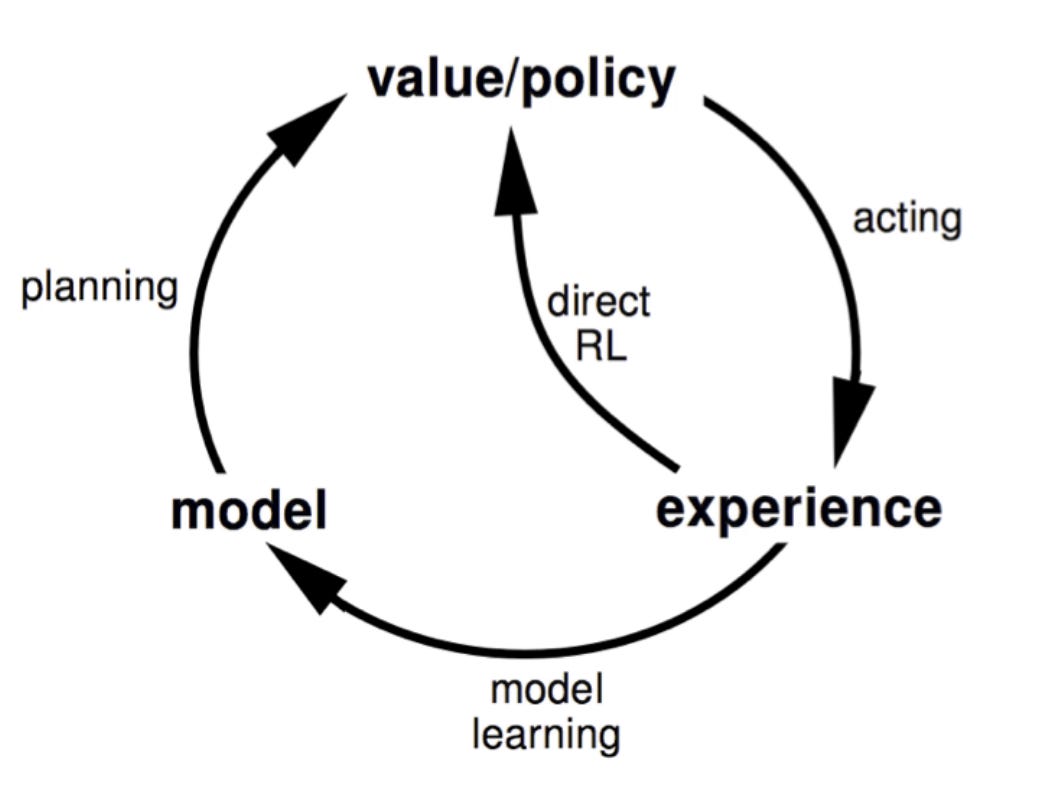
If having a model is so advantageous, why not always use a model-based approach? The answer lies in a classic tradeoff between data efficiency and computational cost.
Model-based approaches are data-efficient. A single real-world interaction can be used to update the policy for many states through simulation. However, this comes at a high computational cost, as the planning phase can involve sweeping over millions of states. Chess is an example where Model based RL can be applied.
Model-free methods are computationally lean per update, making them fast and scalable. The downside is they are extremely data-hungry, often requiring thousands or millions of visits to a state-action pair to get a reliable value estimate.
The choice depends on whether you have an accurate model and whether the cost of computation is more prohibitive than the cost of gathering data.
An agent learning from interaction must answer two fundamental questions: "Given my current strategy, what is the expected outcome?" and "What is the best possible strategy to maximize my outcome?" This distinction between evaluating a strategy and finding a better one forms the core duality of prediction and control.
The first question addresses the prediction problem, or policy evaluation. Imagine forecasting a company's long-term revenue based on a fixed business strategy. Your task is not to create a new strategy but to assess the value of the existing one.
In RL, when an agent follows a fixed policy (π), its actions are predetermined. This simplifies the environment into a Markov Reward Process (MRP), where the agent experiences state transitions and rewards without making decisions. The task is purely evaluative: to calculate the value function for the given policy, which quantifies the expected cumulative reward from each state.
The second, more ambitious question defines the control problem: finding the optimal policy (π*). Here, the agent must learn the best possible strategy from scratch to maximize cumulative reward.
This is the domain of Markov Decision Processes (MDPs), the mathematical framework for sequential decision-making under uncertainty. The goal shifts from predicting outcomes to actively controlling them. The solution to the control problem is a policy that enables the agent to behave optimally.
The prediction and control problems are not independent; they are deeply intertwined. To improve a policy, an agent must first understand its current value, which is precisely what prediction accomplishes. This iterative loop is the engine of most RL algorithms and is known as Generalized Policy Iteration (GPI).
GPI is a "dance" between two alternating processes:
Policy Evaluation (The Critic): We take the current policy, , and compute its state-value function, V^πk . This answers, "Given we follow policy πk, what is the long-term return from each state?"
Policy Improvement (The Actor): Using V^πk as a guide, we improve the policy by acting greedily—choosing the action that leads to the state with the highest estimated value. This forms a new, improved policy, πk+1.
This interaction creates a powerful feedback loop, where the value function and policy are constantly chasing each other toward convergence:
This iterative refinement is guaranteed to converge to the optimal policy (π*) and optimal value function (V*), as each improvement step yields a policy provably better than or equal to the last.
A common misconception is that policy evaluation must fully converge before policy improvement can occur. This is computationally expensive and unnecessary. The robustness of GPI allows these processes to be interleaved. For instance, performing just a single sweep of value updates before improving the policy is often enough to guide the agent in the right direction. This flexibility allows the policy and value function to co-develop and converge towards optimality in a more integrated and often much faster manner.
While model-free and model-based learning are distinct, some of the most powerful ideas in RL bridge the gap between them. What if an agent could start without a map but build one as it explores? This is the idea behind the Certainty Equivalence principle.
The principle is a two-step process:
The agent uses its experience—the stream of (state, action, reward, next_state) tuples—to learn an approximate model of the environment.
It then plans using this learned model as if it were a perfect representation of the world.
To build the model, the agent estimates transition probabilities and rewards from its data. The transition probability
is estimated by dividing the number of times (s, a, s') was observed by the number of times action a was taken in state s. The reward function
is the average reward received after taking action a in state s.
Once this model is constructed, the problem transforms. We can apply model-based planning algorithms, like value iteration, to the approximate model to compute a policy. This approach creates a middle ground in the data-efficiency versus computational cost tradeoff. Like model-based methods, it is highly data-efficient, as a single experience refines the entire world model, allowing that information to be propagated across the state space during planning. However, this comes at the high computational cost of re-computing the model and running planning algorithms, especially for large state spaces.
The GPI framework has a critical flaw: if an agent only acts on what it currently believes is best (exploitation), how can it discover better strategies that lie outside its current knowledge? This requires exploration—trying actions not currently considered optimal to gather new information.
If an agent only exploits, it risks getting trapped in a local optimum. If it only explores, it acts randomly and performs poorly. Effective reinforcement learning requires balancing this trade-off.
One theoretical solution is the assumption of exploring starts, which posits that every episode must begin at a randomly selected state-action pair. Over many episodes, this ensures all state-action pairs are visited, guaranteeing that value estimates will converge to their true optimal values. However, this is often impractical in the real world (e.g., you cannot teleport a physical robot to an arbitrary starting configuration).
A more practical solution is to integrate exploration directly into the agent's policy. The most common method is the ε-greedy (epsilon-greedy) policy:
With probability 1-ε, the agent acts greedily, choosing the action with the highest estimated value (exploitation).
With a small probability ε, the agent chooses an action at random from all available options (exploration).
This simple mechanism ensures the agent continues to try every action in every state, preventing it from committing prematurely to a suboptimal policy. The constant chance of exploration guarantees that the agent never stops learning.
We’ve explored the core principles of model-free learning, highlighting the fundamental duality between prediction (evaluating a policy) and control (finding an optimal one). This relationship is driven by Generalized Policy Iteration, an elegant iterative process that involves evaluating and improving policies. Achieving this balance between exploiting known information and exploring new possibilities is crucial. Mastering these concepts forms the foundation upon which the entire architecture of modern reinforcement learning is built.
Thank you so much for taking the time to read through my thoughts. This newsletter is a small space where I share my learnings and explorations in RL, Generative AI, and beyond as I continue to study and grow. If you found value here, I’d be honored if you subscribed and shared it with friends who might enjoy it too. Your feedback means the world to me, and I genuinely welcome both your kind words and constructive critiques.
With heartfelt gratitude,
Thank you for being part of Neuraforge!
Narasimha Karthik J