
Every LLM capable of generating text, understanding the language and performing various linguistic tasks accurately has undergone multiple stages of training on enormous amounts of text. This is because the deep learning model consists of learnable weights that are updated and tuned through training, making it more suitable and capable of performing many tasks at the human level. In this blog, let’s explore and understand more about an important technique used to train large language models called Pretraining.
Pretraining is the process of training the LLMs by providing significant amounts (i.e. GBs and PBs) of unstructured data or text for the model to understand the underlying information and patterns of the text. Before pretraining, the deep learning model is initialized with random learnable weights or parameters. These weights are updated through the model training with large text datasets that result in these weights understanding and learning the essential patterns from the data.
Pretraining involves training the LLMs by providing the exact text as inputs and outputs. Still, outputs are right-shifted by one token, i.e. the input consists of n tokens, and the outputs will have n+1 tokens, with the task of predicting the (n+1)th token in the output. This task is called next-word prediction, a type of Self-Supervised learning algorithm.

The above image shows that the output text is the input with an additional token to be generated.
Self-supervised learning is a type of machine learning where the model learns to represent and understand the training data patterns without learning from explicitly labelled data. Since the input data also acts as the output or labelled data, pretraining can be classified as a self-supervised learning algorithm. This pretraining technique is the first foundational step for developing large language models.
Pretraining is usually performed as the initial training step of the LLM before finetuning it for a particular task. LLMs' pretraining varies for different models depending on the model's architecture. Let’s explore how pretraining is performed for encoder-only, decoder-only and encoder-decoder-only model types of the transformer model.
Encoder-only models or Autoencoding models are pre-trained with the masked language modelling objective. Encoder-only models are best suited for tasks related to feature extraction from input text, i.e. sentiment analysis, text classification and named entity recognition, to name a few.
Masked Language Modelling learns to predict the masked token in the sequence by attending to both the left-side and right-side context of the masked token. This type of context is called a Bi-directional context. Some of the open-sourced pre-trained models are BERT, Roberta, etc.
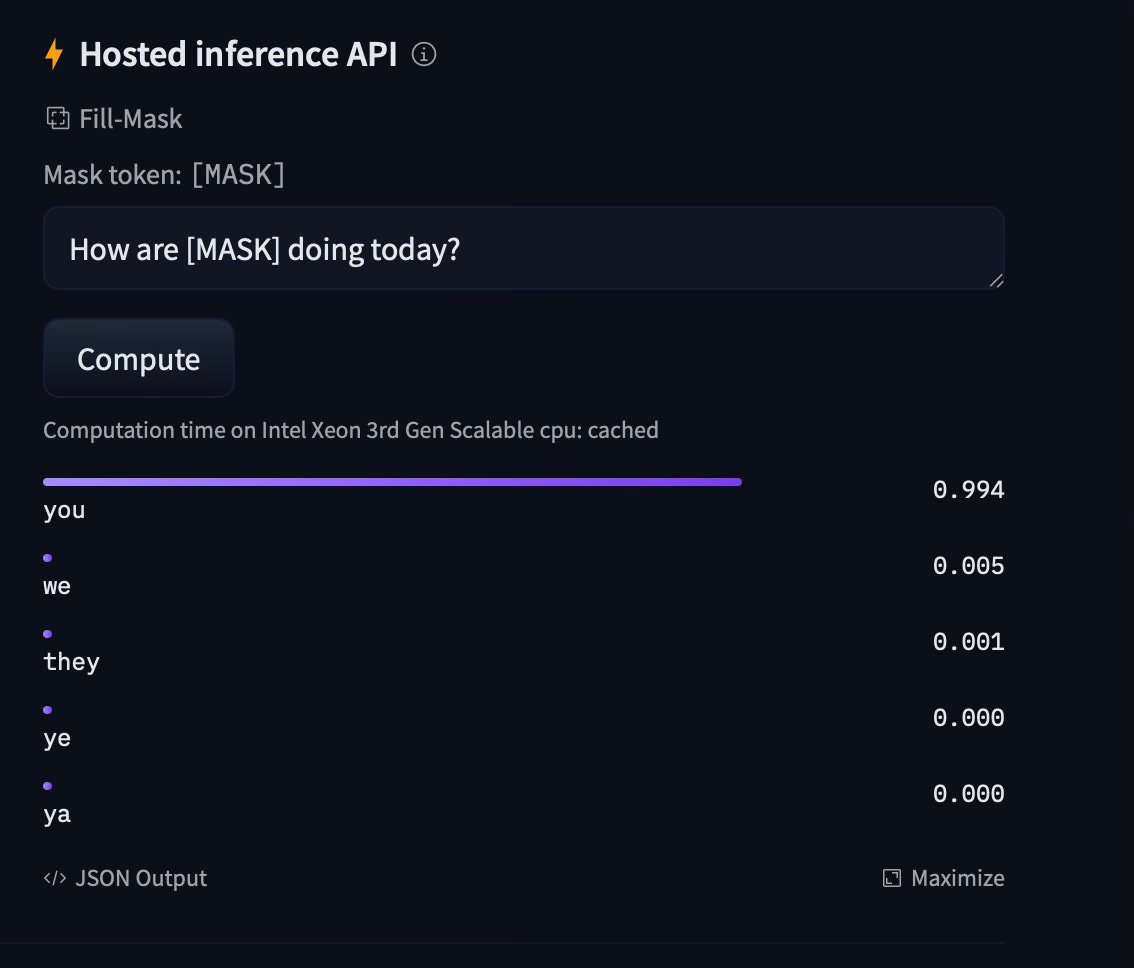
In the above image, the input fed to the BERT model consists of the mask token. The model trained on masked language modelling objectives predicts the token to fill the mask token.
Decoder-only models or Autoregressive models are pre-trained with the Casual Language modelling objective. Decoder-only models are best suited for language modelling tasks, i.e. text generation or next-word prediction.
Casual Language Modelling learns to predict the next token by considering the left side context (or the context of the past tokens) only to predict the new token. This type of context is called a Uni-Directional context. This ensures that the model will learn to predict the next word by attending to the past tokens only. Some examples of pre-trained decoder-only models include the GPT series, Llama series and BLOOM.

In the above example, the GPT2 model generated the text using the next word prediction task for the input prompt provided.
The Encoder-decoder type models or sequence-to-sequence models usually perform tasks by taking in the input sequence and generating the output sequence. The objective of sequence-to-sequence models varies from the task and model being considered.
Some prominent use cases of sequence-to-sequence tasks are machine translation, summarization and question-answering. Commonly available models like T5 and BART are examples of the encoder-decoder types of models.
Usually, pretrained models are called foundation models as they consist of the basic information about the world, i.e. based on the dataset it is trained on. These models are very costly to train from scratch, i.e. regarding data, compute and total training time. Some examples of the training statistics of popular large language models available are:
GPT2: A 157M parameter decoder-only model trained on the BookCorpus dataset with over 7000 unpublished fiction books and a dataset of 8 million web pages with the casual language modelling objective.
GPT4: A whooping 1.76 trillion parameter multi-modal large language model trained on 45 gigabytes of training data taking approximately 90-100 days for pretraining.
BLOOM: A 178 billion parameter multi-lingual LLM trained on 350B tokens of 59 languages for 3.5 months.
The above models are pretrained for vast amounts of data and time to enable further finetuning on specific tasks easier and faster through Transfer Learning. Performing finetuning on these open-source models will result in democratizing AI, as not all individuals and organizations will have the vast resources and data to perform pretraining from scratch.
To summarize,
Pretraining is a technique in which LLMs are trained with millions of text data and files to learn and detect the patterns from the data.
Pretraining is the initial step performed in the LLM training process. Pretrained models are further finetuned with datasets related to specific tasks under consideration.
Pretraining is a type of self-supervised learning technique.
Masked Language modelling is the pretraining objective for encoder-based models.
Casual Language Modelling is the pretraining objective for decoder-based models.
Pretraining models are costly in terms of computing power, training data and training time required.
Performing finetuning on available pretrained models for our specific tasks and datasets via transfer learning will result in more accurate results than training the model from scratch.
Thanks for reading!