
We have seen some single label classifiers i.e. models which try to assign a single label to the image provided. This can be a cat vs dog classifier or handwritten digits classifier, but at the end of the day, the single-label classifier tries to assign a label to the image provided. This type of classifier does the job of providing an output label perfectly for the given input sample.
But this might become an issue when we use the above model in production settings i.e. we have deployed a web app with a dog vs cat classifier and it is trained up to a good amount of accuracy. But if some users start uploading images of buildings or any non-cat or non-dog images, our model doesn’t understand that the input image is not a dog or cat. It provides the prediction of the image based on the max probability of labels it is trained on. So the model can only tell that the image might be a dog or cat and cannot tell it is not a dog or cat.
Another issue with single-label classifiers is that they can only assign a single label to the image. But if our image consists of multiple objects, this model will classify according to the most dominant object present in the image and ignore others. Hence this doesn’t lead to accurate classification.
The solution for these issues can be addressed by using Multi-Label Classification.
Multi-label classification can be used to assign one or more labels to each input sample (image, text, audio…). This solves the drawbacks of single-label classifier in the following ways:
Let’s see in action on how a multi-label dataset looks like and how training a multi-label classifier is different from a single-label classifier.
For better understanding let’s use the PASCAL dataset, which has more than one kind of classified object per image. Before that first, let’s install and import fastai,
Now let’s download the dataset using the untar_data function,
In the downloaded path, we can see that we have train and test folders containing images along with a train.csv file telling us what labels to use for each image. Let’s inspect it using pandas,
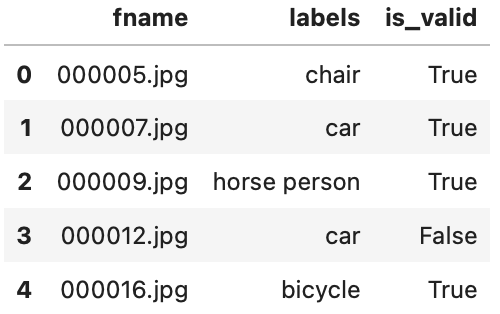
In the train data frame, we can see that it has 3 columns with filename, labels and is_valid.
labels column consisting of one or more categories is separated by a space-delimited string. is_valid is used to determine whether it is used for validation or training.
Now let’s create a datablock object to load the data and create dataloaders. DataBlock is a high-level API that makes data preprocessing and loading easier. Let’s see how to construct one for our application.
Ok now let’s explore each argument passed to the datablock object and see what it does.
The fastai library automatically detects multiple categories and performs one-hot encoding depending on the number of targets available. (But when CategoryBlock is used, ordinal encoding of categories is done i.e for single-label classification)
Now let’s create dataloaders and visualize our dataset,

Since now we have the dataloaders ready, we can now create a model.
Now let’s create a cnn_learner object using the resnet50 pretrained model. But before that let’s understand important differences in the training methods.
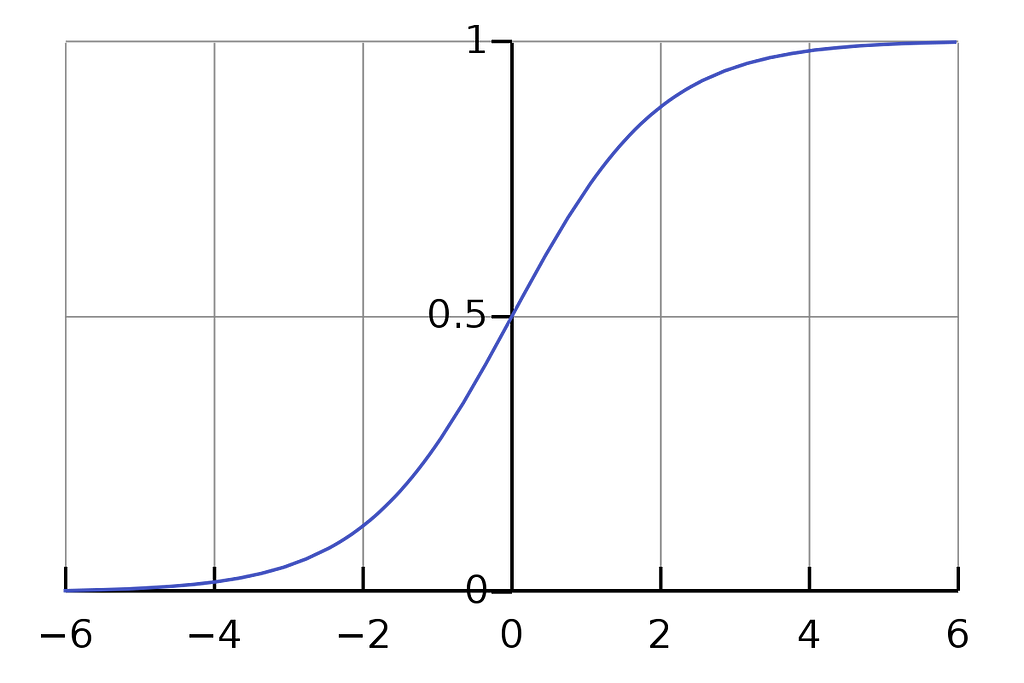
First, let’s discuss some basics of single-label classification. In a binary classification model, the task is to classify any given input into one of two classes. So the loss can be found by applying the sigmoid activation function and passing it through BinaryCrossEntropy loss function. The sigmoid is responsible for converting all values into a range of [0–1].
Since we have all the logits in the range [0–1], we can use the threshold of 0.5 and determine the class of the input sample.
Similarly in a multi-label classification model, the task is to classify given input into one of three or more classes. Here the loss is obtained by first applying the softmax activation function and then passing it through CrossEntropy loss function.
But in a multi-label classification model, the task is to classify given input into more than one class i.e. assigning multiple labels. The targets are represented as a one-hot-encoded array. This seems similar to the binary classification task but with the only difference of having multiple instances of it i.e. binary classification of the input image is done for every label available.
So for this task, we use the BinaryCrossEntropy loss function along with the sigmoid activation function. This is due to the fact that multi-label classification is similar to binary classification, except PyTorch applies the activation and loss to one-hot encoded targets using its element-wise operation.
Fastai provides a metric called accuracy_multi for mult-label classification. After we receive the output logits from the model, sigmoid activation is applied to convert all values into a range of [0–1]. Then the accuracy_multi function is applied by specifying a threshold value i.e. all the probabilities above that thresh will be true else it will be false. In this way, we get the predictions of the model.
The accuracy score is computed by comparing predictions with targets as usual to the normal accuracy calculation. The important thing to keep in mind is to properly determine the value of the threshold. If we are selecting a threshold that is too high, we will only select the objects about which the model is very confident. If we are selecting a threshold that’s too low, we will often be failing to select correctly labelled objects.
Now let’s dive into code and see how to train the model.
Let’s create a learner object using cnn_learner and resnet50 model.
The partial function accepts a function and keyword parameter of that function and returns a new function with the updated keyword parameter. In the above example, we are using partial to update the thresh value of the default accuracy_multi metric function from 0.5 to 0.2.

We can see that when we keep the threshold as 0.2, we are achieving accuracy up to 95 %. Let’s see what happens if we change the thresh value.

In the above code, we have changed the metric of our model to accuracy_multi with thresh=0.1. When we do learn.validate() the learner object calculates the loss and accuracy on our validation data. Since we are only changing the metric, there is no need to train the model. From the above output, we can see that when thresh=0.1, we are getting an accuracy of 93% which is less compared to our previous result. Let’s now check for a higher thresh value.

When we are having a higher threshold value i.e. thresh = 0.99, we can see that the accuracy is 94%. So we can conclude that picking a thresh value is dependent on the data we are using and not a fixed value to be used always.
So it is recommended to experiment and check for different thresh values and decide on a value that gives better accuracy.
Therefore we have seen how the multi-label classifier works and how it can be used to avoid some problems faced by conventional single-label-classifier. So it is always recommended to train a multi-label classifier even for normal/single-label classification tasks for more robust model behaviour.
Thank you
Mlearning.ai Submission Suggestions