
I have discussed in my previous blog post how we can train an out-of-domain input detecting image classifier using a multi-label classification approach. In this blog post let’s discuss how to train a regular multi-class classifier but make it some more intelligent i.e giving it the ability to detect data that it doesn’t know about. We are using the fast.ai library to create and train the model.
Let’s approach the problem by using the PETs dataset. This dataset has 37 categories of different pet breeds with nearly 200 images for each class. More details about this dataset can be found here.
Let’s get started by installing and importing the required libraries.
Now let’s download the PETs dataset,

Since we have downloaded the dataset, let’s build a datablock object and dataloaders.
DataBlock is a high-level API that is used to easily build and load the data i.e. create dataloaders that can directly be served to model. This makes data loading a lot easier and more customizable. Now, let’s create a datablock object according to our dataset.
Now since the datablock object is ready, let’s see in some detail what it is doing,
When the size and min_scale arguments are given, the aug_transform function randomly crops the image to the given size by retaining at least some minimum amount of image data every epoch, which is specified by the min_scale argument.
This datablock object accepts the path to the directory containing images/data as a parameter while loading dataloaders. So now let’s create dataloaders and display some image samples,

Let’s also look at some of the targets,
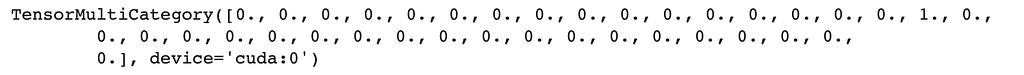
We can see that the target is a one-hot-encoded array with a total of 37 classes. You can check all the labels by dls.vocab .

Now let’s use a pre-trained model and fine-tune it with our data.
Let’s create a learner object using the resnet50 pre-trained model. Since we are using the multi-label classification method to detect unknown labels, we need to change the loss function as well. So we should use the binary cross-entropy loss function or fastai’s BCEWithLogitsLossFlat() loss function with the default threshold value. We should use accuracy_multi with a higher threshold as a metric to ensure only the label with the highest probability is chosen.
To reduce the model size and training time, we are using the half-precision training method by converting all the weights in the model to 16-bit floats. For achieving this to_fp16() is used.
Now let’s look at the code,
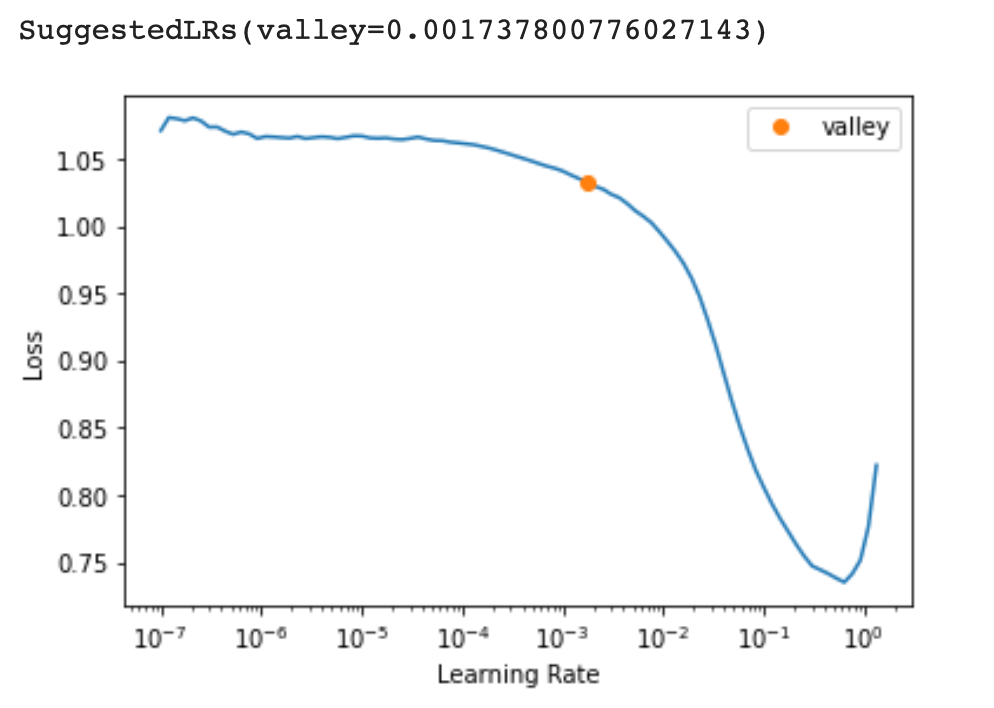
Since we have found the optimal learning rate to use, let’s fine-tune the model for 3 epochs.
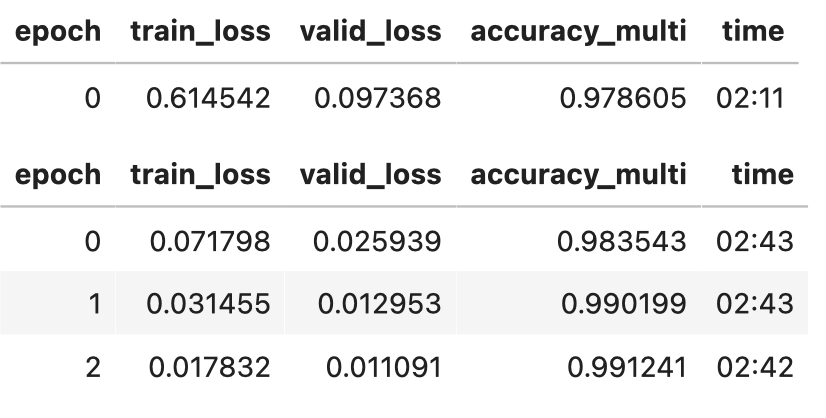
We can see that within 3 epochs of training, our model has got 99% accuracy… This is a pretty impressive result, thanks to the pre-trained resnet50 model. Let’s also look at the loss plot,

Okay, we can see that the training and validation loss has reduced gradually and the model is not overfitting.
Now let’s proceed to model inference, where we can test the unknown label detection in action…
Before inference, let’s update the threshold of our BCEWithLogitsLossFlat() loss function to 0.95. Since the loss function we are using has the sigmoid activation, we should increase the threshold to enable the detection of labels that the model is highly confident about.
Now let’s check some results,

We can see from the above results that our model is doing good on the validation set.
Now let’s do the model inference manually i.e. download some images from the internet and check if the results are matching...
To test the positive case, I have downloaded an image of ‘Bombay cat’ from google images to the notebook location and created a PIL Image object,

Now let’s predict what our model will predict,

Yay... Our model correctly predicted that the class is ‘Bombay’. We can also see that the probability for this class is 0.99… which is pretty high.
Now let’s try to find predictions for some out of domain data. I have downloaded an image of the Eiffel tower from google images and used it for prediction…

Now if we try to find predictions for this image, our model should return negative for all the classes. Let’s find the prediction and check…
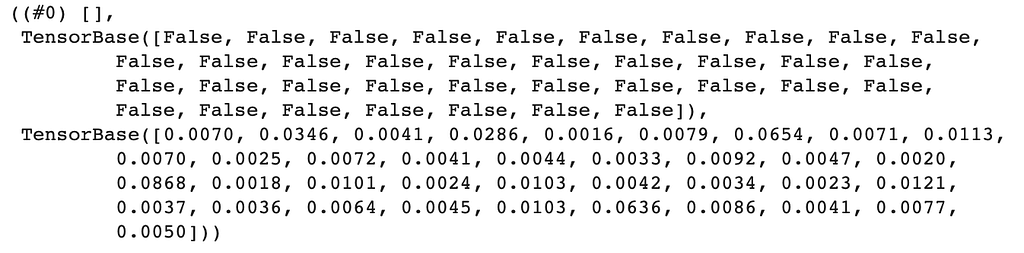
Great!! we can see that our model was able to understand that this image doesn’t belong to any dog or cat breed it was trained for i.e. 37 breeds of pets and returned False for all the available classes.
So from the above results, we can see that using the multi-label classification technique to train a multi-class classification model is the best way to train an intelligent image classifier.
Thank you
Mlearning.ai Submission Suggestions