
This blog post is part of the 100-days of Deep Learning challenge. I have started this challenge by reading the book “Deep Learning for Coders with fastai & PyTorch” by Jeremy Howard and Sylvain Gugger, to learn about the fastai library and its applications in deep learning.
Fastai library is a deep learning library that adds higher-level functionalities on top of PyTorch. So this is a perfect choice of the library for quick prototyping and model building on different datasets as well as utilising the flexibility and speed of PyTorch.
In this blog post, let us discuss the data-centric approach of training deep learning models. Data-centric AI is based on the concept of systematically enhancing the datasets over the course of model development to improve the model metrics. This approach is usually overlooked and data collection and cleaning has not been the most favourite task.
“The model and the code for many applications are basically a solved problem. Now that the models have advanced to a certain point, we got to make the data work as well” — Andrew Ng
Let’s train an image classifier pipeline from scratch i.e. from gathering data to training the model using the fastai library thereby exploring the potential of the data-centric model training approach.
Let’s train a bear detector i.e. it will discriminate between three types of bears: grizzly, black and teddy bear. To obtain the dataset, let’s use the jmd_imagescraper library. This is an image scraping library for creating datasets. It uses the DuckDuckGo for image scraping, hence you can verify the images being downloaded by searching in DuckDuckGo.
Let’s install the required libraries,
Now let’s import the fastai and jmd_imagescraper library,
We have to download the images corresponding to 3 classes i.e. grizzly, black and teddy bear. To download the dataset, we have to pass the path to download, name of the folder, search string and number of results to be downloaded as arguments to download the dataset.
You can check the images downloaded in the Data folder. Since we have downloaded the data from the internet, there are chances that it might be corrupted, so let’s verify and delete the corrupted one.
Fastai provides a variety of util functions which makes it easy to work with. The get_image_files is a fastai function that returns an L object containing the paths to all images. The verify_images function is used to check for corrupted image files in the list.
Since now we have our dataset ready let’s proceed to prepare data for model training.
In PyTorch, DataLoader is a class that takes the dataset and returns an iterable which can be passed to the model for training in batches. Similarly, the DataLoaders class in fastai takes DataLoader objects which we pass and makes them available for training and validation.
To convert our downloaded data into DataLoaders in fastai, the most efficient way is to use the DataBlock API. Using this API, we can easily customize and control every stage in preparing the dataloaders. Let’s define the DataBlock object for the above dataset.
Let’s look at each of the arguments and how it is used,
As of now, we have defined the basic datablock object. Now let’s use it to create dataloaders from the dataset.
Using the show_batch() method we can visualize a few samples present in the dataset. We can expect a similar output as follows,

We can see that we have easily created dataloaders and from raw data without much hassle using DataBlock API.
Now we have the data ready in the format required for model training. Before we delve into training, let’s explore another important part of model pipeline data augmentation.
Data augmentation refers to creating random variations of samples such that they appear different but do not change the meaning of the image. This is one of the ways to ensure that model is not memorizing the input images but learning about the patterns in the data. Let’s look at some of the most commonly used augmentation techniques.
We can create a new datablock object using the new method on the existing datablock and passing the new item and batch transform. The RandomResizedCrop method accepts the min_scale argument which determines how much of the image to select at a minimum each time. Finally, by setting unique=True in show_batch function we can have the same image repeated with different versions of RandomResizedCrop transforms.

You can see a similar output as follows,

Now since we have seen some ways to perform data augmentation let’s combine the methods and get the final dataloaders.
Let’s dive into creating and training the model…
Now coming to the fun part… Since we don’t have a lot of data for our problem, training a model with high accuracy will be difficult without running into the problem of over-fitting. Unless we are using a technique called transfer learning.
Transfer learning is a training method where we use a pre-trained model ( i.e. a model that has been trained previously on different tasks ) and fine-tune with our dataset. This method has proved to achieve amazing results even with less training data and by taking less time. Now let’s see how it is done in fastai,
After training for 4 epochs we can see that the accuracy of the model is closer to 95% and that is pretty impressive.
Now let’s see the confusion matrix to make more sense of the model performance.

From the confusion matrix, we can observe that our model was able to correctly classify almost all images.
In the below table, we can see the images that the model has misclassified with maximum loss. We can see that the first image belongs to the black Bear class but our model has predicted it as Grizzly Bear.
But if we observe the bear image, it resembles more like a grizzly bear than a black bear. So there has been some mess up while labelling the image. (Since these are downloaded directly from DuckDuckGo without our interference)
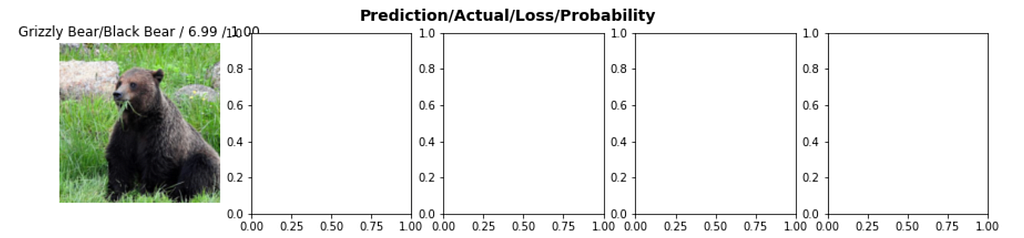
Now since our model is trained, let’s now use the data-centric approach to improve the model. This can be done by examining the data used for training and validation i.e. check if images are labelled correctly and then update it with the correct label.
Intuitively, data cleaning is done before model training. But as we have seen above, the model helps us to identify issues in the data. So to perform data cleaning, fastai provides a handy GUI that allows us to choose a category or delete samples from both training and validation datasets.

We will get the above GUI which displays images with the highest loss in order (i.e. what model think it is not right). Now we can choose the category of the image in the dropdown menu and then perform changes using the following code.
Now we can clean the data easily and again train the model. We will be able to see that the model performance will have improved far better (almost 99~100% accuracy).
The Data-Centric Approach of model training and transfer learning helps us to train models on real-world datasets and achieve state-of-the-art results. Hence there is a need to shift our focus from model-centric AI to data-centric AI and explore the potential of MLOps.
Thank you !!